ChatGPT, Myths and Realities
Everything you wanted to know about Deep Learning but were afraid to ask
2024-10-24
Historical perspective timeline
- 1950s: perceptron (Rosenblatt 1958)
- 1960s: perceptron convergence theorem (Minsky and Papert 1969)
- 1970s-1980s: backpropagation (Rumelhart, Hinton, and Williams 1986)
- 1990s: SVM (Cortes and Vapnik 1995)
- 2000s: Boosting (Freund and Schapire 1997), Random Forests (Breiman 2001)
- 2010s: Deep Learning (Goodfellow, Bengio, and Courville 2016)


Train a neural network
Foreword, beware the Alchemy
More or less theoretical guarantees
- field of research
- type of network
- from theory to applications: a gap
Myriad of ad-hoc choices, engeenering tricks and empirical observations
Current choices are critical for success: what are their pros and cons?
Try \rightarrow Fail \rightarrow Try again is the current pipeline
Science and/or Alchemy?
![]()
- Criticable current state of Deep Learning research,
- lack of scientific rigor in the field.
![]()
- arguing that mathematical rigor is not critical in Deep Learning research
- the field is doing just fine without it.
Criticizing an entire community (and an incredibly successful one at that) for practicing “alchemy”, simply because our current theoretical tools haven’t caught up with our practice is dangerous. Why dangerous? It’s exactly this kind of attitude that lead the ML community to abandon neural nets for over 10 years, despite ample empirical evidence that they worked very well in many situations. (Yann LeCun, 2017, My take on Ali Rahimi’s “Test of Time” award talk at NIPS.)
The main ingredients
- Tensor algebra (linear algebra)
- Automatic differentiation
- (Stochastic) Gradient descent
- Optimizers
- Non-linearities
- Large datasets
Also, on hardware side:
- GPU
- Distributed computing
shape=(batch, height, width, features)
Automatic differentiation
- chain rule to compute gradient with respect to \theta
- key tool: backpropagation
- don’t need to store the computation graph entirely
- gradient is fast to compute (a single pass)
- but memory intensive
f(x)=\nabla\frac{x_{1}x_{2} sin(x_3) +e^{x_{1}x_{2}}}{x_3}
\begin{darray}{rcl} x_4 & = & x_{1}x_{2}, \\ x_5 & = & sin(x_3), \\ x_6 & = & e^{x_4}, \\ x_7 & = & x_{4}x_{5}, \\ x_8 & = & x_{6}+x_7, \\ x_9 & = & x_{8}/x_3. \end{darray}
(More than) a pinch of non-linearities
- Linear Transformations + Non-linear activation functions
- radically enhance the expressive power of the model
- ability to explore the space of functions in gradient descent.

BERT: Bidirectional Encoder Representations from Transformers
- embeddings: represent words as vectors in high dimensions
Transformers

Training using humans
- pretraining (unsupervised learning): fill blanck, attention mechanisms, next word
- fine-tuning (supervised learning): specific dialogues, hyperparameters tuning
- RLHF (reinforcement learning): workers give feedback and possible rewards + exploration
Training ChatGPT: locations is impactful
- leftmost: from Canada / Switzerland to India and West South Africa (x50 factor)
“Outsourcing trauma to the developing world”
- workers are approached in Kibera, the largest informal settlement in Africa
- salaries too low to improve their situation, only keep it
Concerns on the scientific side
lack of theoretical understanding, trial and error only
\Rightarrow engineering ad-hoc solutions, giant panels of knobs to turn
race to performance impacting reviews quality and content
- stressful for engineers and researchers,
- new jobs appear and disappear with trends
\Rightarrow replacing domain specialists and researchers
![]()
The Bestiary IV, Recurrent Neural Networks
For sequences (first DL models for NLP and speech recognition).

The Bestiary V, Graph Neural Networks
Encodes graph structure (nodes, edges, global) into embedding vectors
Use those vectors as input to a network.
Attention mechanism \Rightarrow breakthrough of protein folding prediction with AlphaFold of DeepMind.
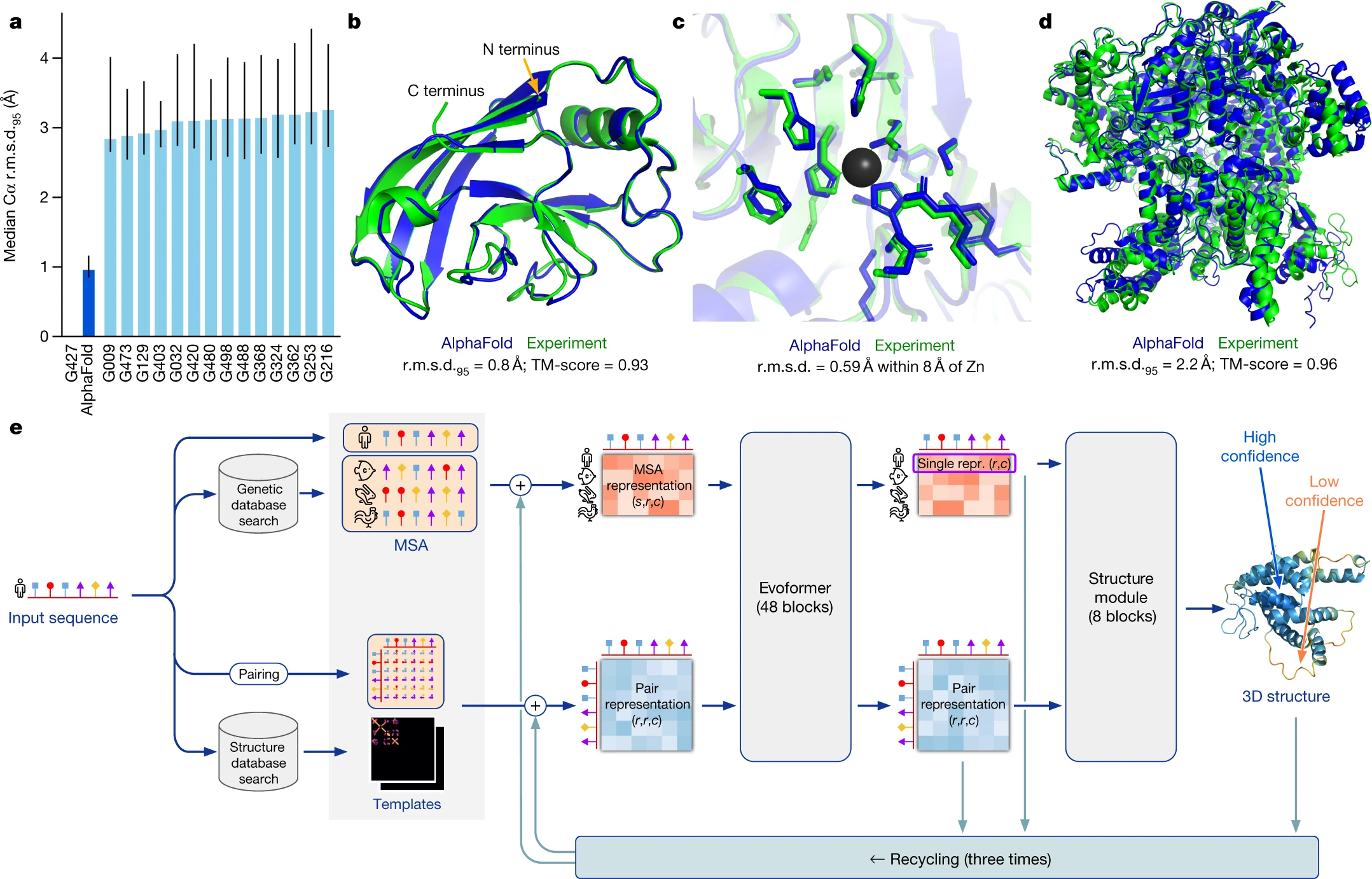
Jumper et al. (2021)
The Bestiary VI, Generative Adversarial Networks
GAN
[generative adversarial network for celebrity faces] (https://towardsdatascience.com/generative-adversarial-network-gan-for-dummies-a-step-by-step-tutorial-fdefff170391)
Tokens vs embeddings
- (token: atomic unit) \neq (embedding: vector representation)
Tokenize the word: tokenizer
['token', '##izer']pipeline to train a representation model (like BERT):
tokenize text \rightarrowmap token to a unique id \rightarrow map id to randomized initial vector \rightarrowtrain
BERT training set=books + wikipedia: Word completion + next sentence prediction
![]()