
Scientific communication: including talks, (pre)-publications, code and slides when available. In fine the serious page.
Thesis
Label ambiguity in crowdsourcing for classification and expert feedback supervised by B. Charlier , A. Joly and J. Salmon at the University of Montpellier and INRIA ZENITH Montpellier. (2021-2024) [thesis][slides]
Publications
Journals
-
2026 Bayesian Implementation of the Factor‐Analytic Mixed Model and Application to Embeddings by A. Marchal , M. Lamure, T. Lefort , and F. Imbach in Wiley Stat 15
Abstract: Mixed models and neural networks each offer complementary frameworks for prediction. Theoretically grounded in inference,mixed models can unveil latent variance structure notably with the factor-analytic approach. In this article, we propose to bridgethe gap between the two frameworks, leveraging embedding data from a neural network encoder to structure the covariancematrix in a mixed model. First, we implemented a Bayesian factor-analytic mixed model and challenged it using simulations. Themodel showed sensitivity to the prior, with a propensity to overfitting under some hyperparameterizations. However, with anappropriate hyperparameterization it showed high predictive performance and a good ability to infer the latent structure (accu-racy between 0.881 and 0.919 on the two first factorial axes). Using a challenging design in which each individual was observeda single time in a single environment, we showed that the embedding information enabled prediction of unobserved individuals. A small but significant (p-value < 0.05) amount of real bibliometric data variance was captured using this factor-analytic compo-nent applied within a negative-binomial mixed model. These results call for further investigation of the use of the mixed modelframework to analyse embedding data.[wiley]
-
2026 Cooperative learning of Pl@ntNet's Artificial Intelligence algorithm: how does it work and how can we improve it? by T. Lefort , A. Affouard , B. Charlier , J-C. Lombardo , M. Chouet, H. Goëau , J. Salmon , P. Bonnet and A. Joly in Wiley Methods in Ecology and Evolution 17 (392-403)
Abstract: Deep learning models for plant species identification rely on large annotated datasets. The PlantNet system enables global data collection by allowing users to upload and annotate plant observations, leading to noisy labels due to diverse user skills. Achieving consensus is crucial for training, but the vast scale of collected data makes traditional label aggregation strategies challenging. Existing methods either retain all observations, resulting in noisy training data or selectively keep those with sufficient votes, discarding valuable information. Additionally, as many species are rarely observed, user expertise can not be evaluated as an inter-user agreement: otherwise, botanical experts would have a lower weight in the AI training step than the average user. Our proposed label aggregation strategy aims to cooperatively train plant identification AI models. This strategy estimates user expertise as a trust score per user based on their ability to identify plant species from crowdsourced data. The trust score is recursively estimated from correctly identified species given the current estimated labels. This interpretable score exploits botanical experts' knowledge and the heterogeneity of users. Subsequently, our strategy removes unreliable observations but retains those with limited trusted annotations, unlike other approaches. We evaluate PlantNet's strategy on a released large subset of the PlantNet database focused on European flora, comprising over 6M observations and 800K users. We demonstrate that estimating users' skills based on the diversity of their expertise enhances labeling performance. Our findings emphasize the synergy of human annotation and data filtering in improving AI performance for a refined dataset. We explore incorporating AI-based votes alongside human input. This can further enhance human-AI interactions to detect unreliable observations.[Hal] [zenodo] [Peerannot tutorial] [MEE]
Abstract: Crowdsourcing is a quick and easy way to collect labels for large datasets, involving many workers. However, workers often disagree with each other. Sources of error can arise from the workers’ skills, but also from the intrinsic difficulty of the task. We present peerannot: a Python library for managing and learning from crowdsourced labels for classification. Our library allows users to aggregate labels from common noise models or train a deep learning-based classifier directly from crowdsourced labels. In addition, we provide an identification module to easily explore the task difficulty of datasets and worker capabilities.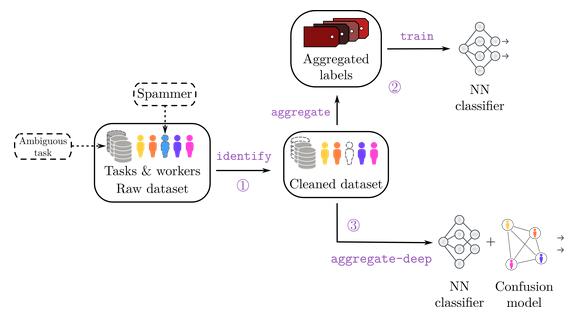 2024 Peerannot: classification for crowdsourced image datasets with Python
by T. Lefort , B. Charlier , A. Joly and J. Salmon in Computo
2024 Peerannot: classification for crowdsourced image datasets with Python
by T. Lefort , B. Charlier , A. Joly and J. Salmon in Computo
-
2024 Identify ambiguous tasks combining crowdsourced labels by weighting Areas Under the Margin by T. Lefort , B. Charlier , A. Joly and J. Salmon in TMLR
Abstract: In supervised learning - for instance in image classification - modern massive datasets are commonly labeled by a crowd of workers. The obtained labels in this crowdsourcing setting are then aggregated for training. The aggregation step generally leverages a per-worker trust score. Yet, such worker-centric approaches discard each task's ambiguity. Some intrinsically ambiguous tasks might even fool expert workers, which could eventually be harmful to the learning step. In a standard supervised learning setting - with one label per task - the Area Under the Margin (AUM) is tailored to identify mislabeled data. We adapt the AUM to identify ambiguous tasks in crowdsourced learning scenarios, introducing the Weighted AUM (WAUM). The WAUM is an average of AUMs weighted by task-dependent scores. We show that the WAUM can help discard ambiguous tasks from the training set, leading to better generalization or calibration performance. We report improvements over existing strategies for learning a crowd, both for simulated settings and for the CIFAR-10H, LabelMe and Music crowdsourced datasets.[ArXiv][slides] [Openreview]
In Proceedings of Conferences
International Conferences
Abstract: Numerical validation is at the core of machine learning research as it allows to assess the actual impact of new methods, and to confirm the agreement between theory and practice. Yet, the rapid development of the field poses several challenges: researchers are confronted with a profusion of methods to compare, limited transparency and consensus on best practices, as well as tedious re-implementation work. As a result, validation is often very partial, which can lead to wrong conclusions that slow down the progress of research. We propose Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. Benchopt simplifies benchmarking for the community by providing an off-the-shelf tool for running, sharing and extending experiments. To demonstrate its broad usability, we showcase benchmarks on three standard learning tasks: l2-regularized logistic regression, Lasso, and ResNet18 training for image classification.These benchmarks highlight key practical findings that give a more nuanced view of the state-of-the-art fort hese problems, showing that for practical evaluation, the devil is in the details. We hope that Benchopt will foster collaborative work in the community hence improving the reproducibility of research findings. June 2022: Benchopt: Reproducible, efficient and collaborative optimization benchmarks, NeurIPS 2022 by T. Moreau , M. Massias , A. Gramfort , P. Ablin , B. Charlier , P.-A. Bannier , M. Dagréou , T. Dupré la Tour, G. Durif , C. F. Dantas , Q. Klopfenstein , J. Larsson , E. Lai, T. Lefort , B. Malézieux , B. Moufad , T. B. Nguyen , A. Rakotomamonjy , Z. Ramzi , J. Salmon and S. Vaiter
June 2022: Benchopt: Reproducible, efficient and collaborative optimization benchmarks, NeurIPS 2022 by T. Moreau , M. Massias , A. Gramfort , P. Ablin , B. Charlier , P.-A. Bannier , M. Dagréou , T. Dupré la Tour, G. Durif , C. F. Dantas , Q. Klopfenstein , J. Larsson , E. Lai, T. Lefort , B. Malézieux , B. Moufad , T. B. Nguyen , A. Rakotomamonjy , Z. Ramzi , J. Salmon and S. Vaiter
National Conferences
-
Abstract: Crowdsourcing has emerged as a pivotal paradigm for harnessing collective intelligence to solve data annotation tasks. Effective label aggregation, crucial for leveraging the diverse judgments of contributors, remains a fundamental challenge in crowdsourcing systems. This paper introduces a novel label aggregation strategy based on Shapley values, a concept originating from cooperative game theory. By integrating Shapley values as worker weights into the Weighted Majority Vote label aggregation (WMV), our proposed framework aims to address the interpretability of weights assigned to workers. This aggregation reduces the complexity of probabilistic models and the difficulty of the final interpretation of the aggregation from the workers’ votes. We show improved accuracy against other WMV-based label aggregation strategies. We demonstrate the efficiency of our strategy on various real datasets to explore multiple crowdsourcing scenarios.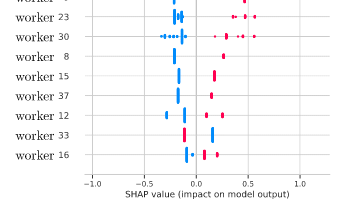 July 2024: Weighted majority vote using Shapley values in crowdsourcing, CAp 2024 by T. Lefort , B. Charlier , A. Joly and J. Salmon .
July 2024: Weighted majority vote using Shapley values in crowdsourcing, CAp 2024 by T. Lefort , B. Charlier , A. Joly and J. Salmon .
[paper]
-
May 2024: peerannot: A framework for label aggregation in crowdsourced datasets, JDS 2024 by A. Dubar, T. Lefort and J. Salmon .
Abstract: Ce travail présente peerannot, une librairie de classification de données dont les étiquettes sont générées par production participative. Elle est écrite en Python et permet d’établir une comparaison des méthodes de classification par agŕegation avec d'utres librairies de référence.[paper]
-
May 2024: Cooperative learning of Pl@ntNet’s Artificial Intelligence algorithm using label aggregation, JDS 2024 by T. Lefort , A. Affouard B. Charlier , J. Salmon P. Bonnet and A. Joly .
Abstract: The Pl@ntNet system enables global data collection by allowing users to upload and annotate plant observations, leading to noisy labels due to diverse user skills. Achieving consensus is crucial for training, but the vast scale of collected data makes traditional label aggregation strategies challenging. Additionally, as many species are rarely observed, user expertise can not be evaluated as an inter-user agreement: otherwise, botanical experts would have a lower weight in the training step than the average user as they have fewer but precise articipation. Our proposed label aggregation strategy aims to cooperatively train plant identification models. This strategy estimates user expertise as a trust score per worker based on their ability to identify plant species from crowdsourced data. The trust score is recursively estimated from correctly identified species given the current estimated labels. This interpretable score exploits botanical experts’ knowledge and the heterogeneity of users. We evaluate our strategy on a large subset of the Pl@ntNet database focused on European flora, comprising over 6 000 000 observations and 800 000 users. We demonstrate that estimating users’ skills based on the diversity of their expertise enhances labeling performance.[paper]
-
July 2023: Weighting areas under the margin in crowdsourced datasets, JDS 2023 by T. Lefort , B. Charlier , A. Joly and J. Salmon .
Abstract: In supervised learning — for instance in image classification — modern massive datasets are commonly labeled by a crowd of workers. Labeling errors can happen because of the workers abilities or tasks identification difficulty. Some intrinsically ambiguous tasks might fool expert workers, which could eventually be harmful to the learning step. In a standard supervised learning setting — with one label per task — the Area Under the Margin (AUM) is tailored to identify mislabeled data. We adapt the AUM to identify ambiguous tasks in crowdsourced learning scenarios, introducing the Weighted AUM (WAUM). The WAUM is an average of AUMs weighted by task-dependent scores. We show that the WAUM can help discard ambiguous tasks from the training set, leading to better generalization or calibration performance.[paper]
-
Abstract: It is common to collect labeled datasets using crowdsourcing. Yet, label quality depends deeply on the task difficulty and on the workers' abilities. With such datasets, the lack of ground truth makes it hard to assess the quality of annotations. There are few open-access crowdsourced datasets, and even fewer that provide both heterogeneous tasks in difficulty and all workers' answers before the aggregation. We propose a new crowdsourcing simulation framework with quality control. This allows us to evaluate different empirical learning strategies empirically from the obtained labels. Our goal is to separate different sources of noise: workers that do not provide any information on the true label against poorly performing workers, useful on easy tasks.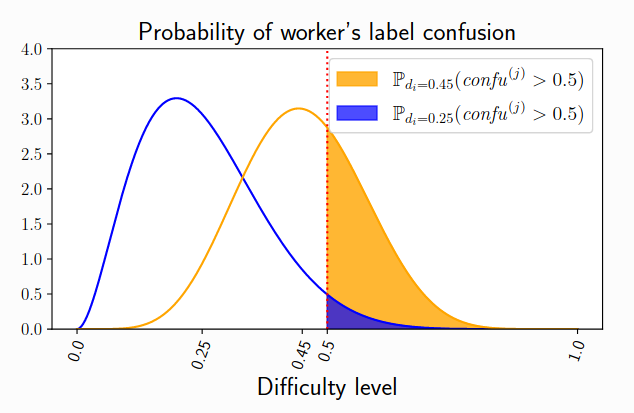 June 2022: Crowdsourcing label noise simulation on image classification tasks, JDS 2022 by T. Lefort , B. Charlier , A. Joly and J. Salmon .
June 2022: Crowdsourcing label noise simulation on image classification tasks, JDS 2022 by T. Lefort , B. Charlier , A. Joly and J. Salmon .
[paper]
Talks
-
January 2024: Enhancing Crowdsourced Plant Identification: From Label Aggregation to Personalized Recommendations at INRAE Paris-Saclay [slides]
-
November 2024: Keeping humans in the loop via citizen science at Univ. Lille. [slides]
-
July 2024: Crowdsourcing and citizen science: how to handle our data? at INRIA Lille, SCOOL team. [slides]
-
May 2024: Cooperative data enrichment algorithms at Journées des Statistiques de France (JDS) 2024 Univ. Bordeaux. [slides]
-
Abstract: Deep learning models for plant species identification rely on large annotated datasets. The Pl@ntNet system enables global data collection by allowing users to upload and annotate plant observations, leading to noisy labels due to diverse user skills. Achieving consensus is crucial for training, but the vast scale of collected data (number of observations, users and species) makes traditional label aggregation strategies challenging. Existing methods either retain all observations, resulting in noisy training data or selectively keep those with sufficient votes, discarding valuable information. Additionally, as many species are rarely observed, user expertise can not be evaluated as an inter-user agreement: otherwise, botanical experts would have a lower weight in the AI training step than the average user. Our proposed label aggregation strategy aims to cooperatively train plant identification AI models. This strategy estimates user expertise as a trust score per worker based on their ability to identify plant species from crowdsourced data. The trust score is recursively estimated from correctly identified species given the current estimated labels. This interpretable score exploits botanical experts’ knowledge and the heterogeneity of users. Subsequently, our strategy removes unreliable observations but retains those with limited trusted annotations, unlike other approaches. We evaluate our strategy on a large subset of the Pl@ntNet database focused on European flora, comprising over 6M observations and 800K users. This anonymized dataset of votes and observations is released [openly](https://doi.org/10.5281/zenodo.10782465). We demonstrate that estimating users’ skills based on the diversity of their expertise enhances labeling performance. Our findings emphasize the synergy of human annotation and data filtering in improving AI performance for a refined training dataset. We explore incorporating AI-based votes alongside human input in the label aggregation. This can further enhance human-AI interactions to detect unreliable observations (even with few votes).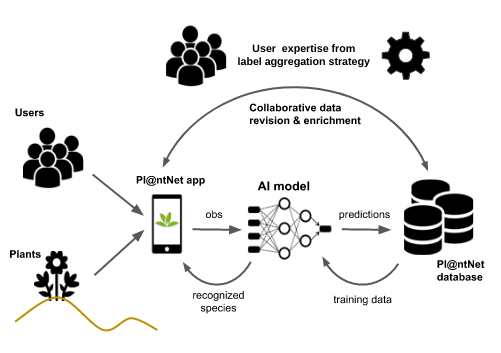 March 2024 Apprentissage collaboratif d'espèces de plantes et agrégation de labels dans Pl@ntNet IA-ECO seminar , UMR MARBEC
March 2024 Apprentissage collaboratif d'espèces de plantes et agrégation de labels dans Pl@ntNet IA-ECO seminar , UMR MARBEC
[slides]
-
Abstract: Many of us have seen the strong impact of so-called Deep Learning technologies for some time now. This is particularly true of their "generative" side, with Large Language Models (LLMs) such as ChatGPT, GPT-4, etc., whose use has become widespread in higher education, inviting teaching staff to question these tools, from their creation to their use. Here, we offer an overview of Deep Learning, taking a look at what data-driven learning is, and introducing the flagship of these new technologies: LLMs, their development, and uses.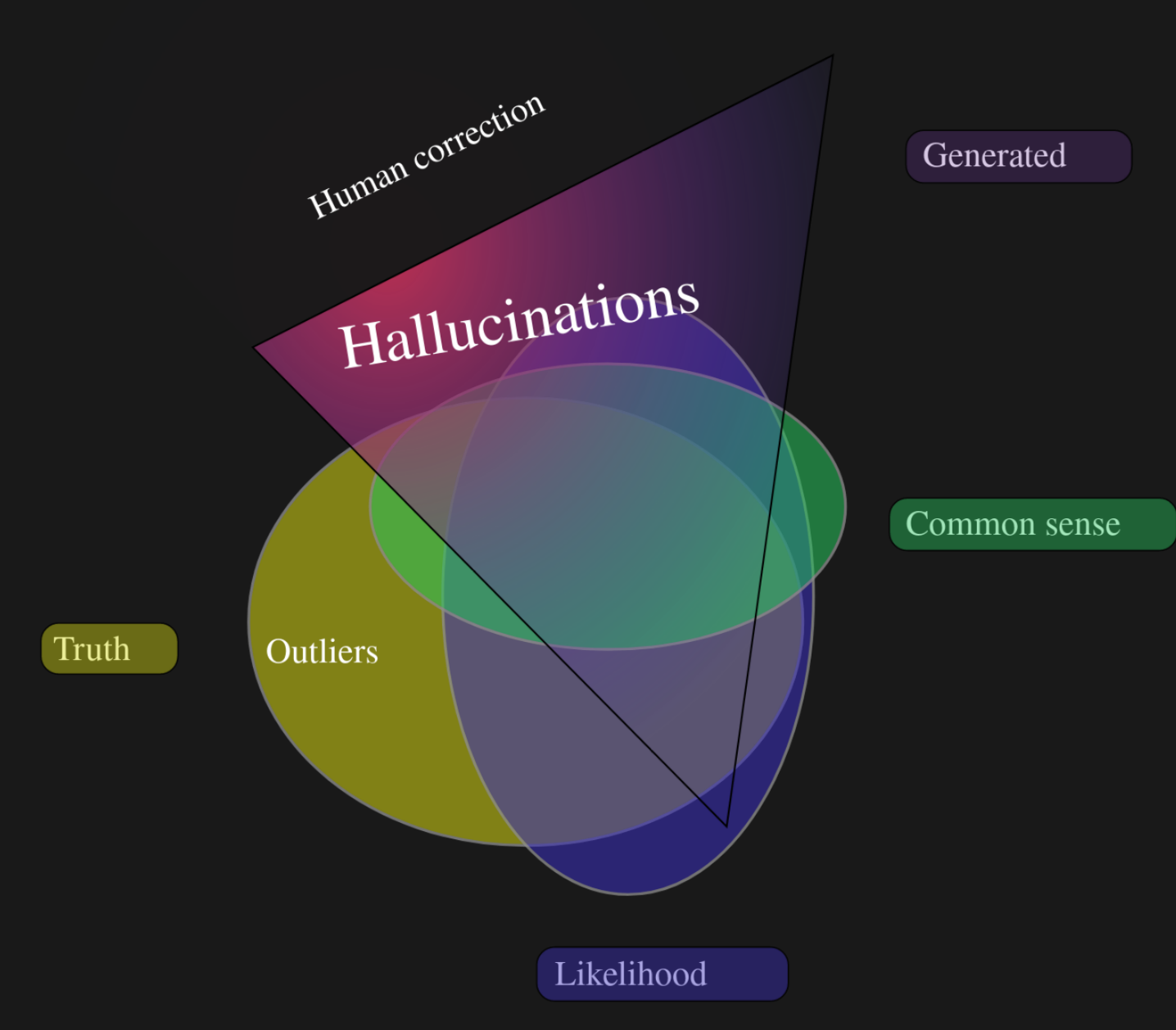 October 2023: ChatGPT & co, Myths and Reality. Everything you wanted to ask about Deep Learning but did not dare to Séminaire culture générale, with Francois David Collin IMAG
October 2023: ChatGPT & co, Myths and Reality. Everything you wanted to ask about Deep Learning but did not dare to Séminaire culture générale, with Francois David Collin IMAG
-
September 2023: Data collection from a crowd: where is the noise coming from? PhD students seminar, IMAG, Univ. Montpellier.
Abstract: Citizen science can increase public engagement, improve our knowledge and help models perform better. Keeping humans in the loop is a way to obtain more data, faster, at a lesser cost than if we asked experts all the time. However, citizen science often comes with an issue: we collect noisy data from a crowd of workers. For example, in image classification, what can we do when workers disagree on the label of a given image? If there is no consensus, who is at fault? Is the mistake coming from the workers’ abilities or is the image simply not clear enough to be labeled? In this talk, we present different ways to learn from crowdsourced data. In particular, we look back to how datasets were created and how label ambiguities can naturally happen along the way. - July 2023: Weighting areas under the margin in crowdsourced datasets at Journées des Statistiques de France (JDS) 2023 Univ. Bruxelles.
-
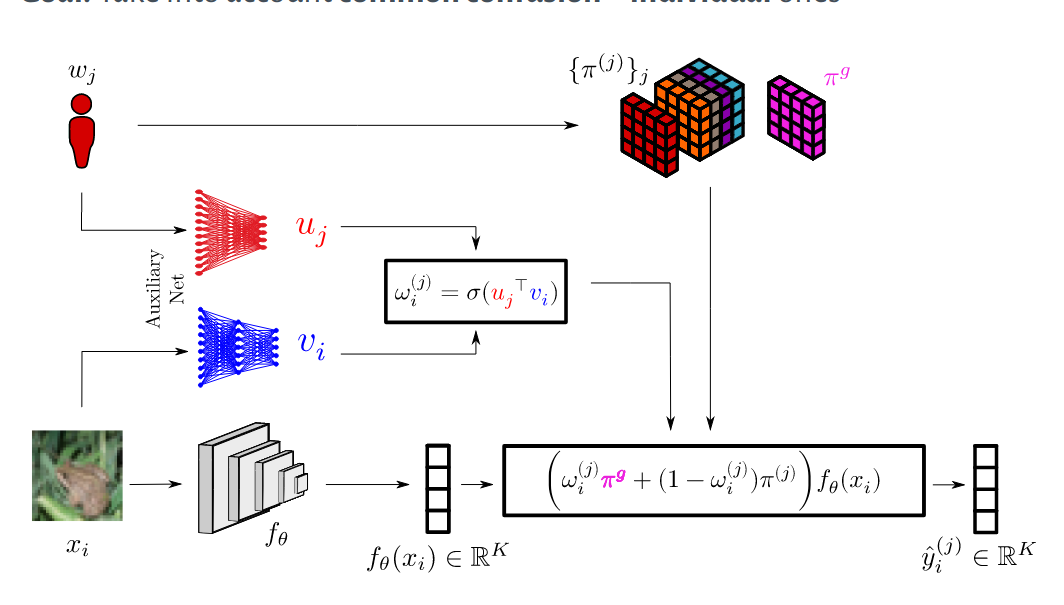 February 2023: ML-MTP Learning from crowds: going beyond aggregation schemes Univ. Montpellier IMAG
February 2023: ML-MTP Learning from crowds: going beyond aggregation schemes Univ. Montpellier IMAG
[slides]
-
October 2022: ML-MTP Improve learning combining crowdsourced labels by weighting Areas Under the Margin Univ. Montpellier IMAG [slides]
-
July 2022: GDR MaDICS “Gongshow” and poster session at Quatrième édition du Symposium MaDICS - Univ. Lyon
-
Abstract: It is common to collect labeled datasets using crowdsourcing. Yet, label quality depends deeply on the task difficulty and on the workers' abilities. With such datasets, the lack of ground truth makes it hard to assess the quality of annotations. There are few open-access crowdsourced datasets, and even fewer that provide both heterogeneous tasks in difficulty and all workers' answers before the aggregation. We propose a new crowdsourcing simulation framework with quality control. This allows us to evaluate different empirical learning strategies empirically from the obtained labels. Our goal is to separate different sources of noise: workers that do not provide any information on the true label against poorly performing workers, useful on easy tasks.
June 2022: Crowdsourcing label noise simulation on image classification tasks at Journées des Statistiques de France (JDS) 2022 Univ. Lyon.
[slides]
-
June 2022: Workshop: How to create a professional and personal website easily at SemDoc (PhD seminar) - Univ. Montpellier IMAG
-
April 2022: Statlearn Springschool workshop on upcoming trends in statistical learning, poster session - Cargèse Corsica
-
November 29 2021: High dimensional optimization for penalized linear models with interactions using graphics card computational power, at Probability and statistics (EPS) team seminar - Univ. Montpellier IMAG (content from my master's thesis internship)
Abstract: Linear models are used in statistics for their simplicity and the interpretability of the results. On genomics datasets, large dimensions need robust methods that induce sparsity to select interpretable active features for biologists. In addition to the main features, we also capture the effects of the interactions, which increase the dimension of the problem and the multicolinearity. To counteract these issues, we use the Elastic-Net on the augmented problem. Coordinate Descent is mostly used nowadays for that, but there are other methods available. We exploit the structure of our problem with first order interactions to use parallelized proximal gradient descent algorithms. Those are known to be more computationally demanding in order of magnitude, but parallelizing on a graphics card let us be as fast or faster in some situations. - October 28 2021: Introduction to neural network with Joseph Salmon, at ML-MTP seminar - Univ. Montpellier IMAG. (session 0 for reading group on Deep Learning: a statistical viewpoint)
[slides] [code]
-
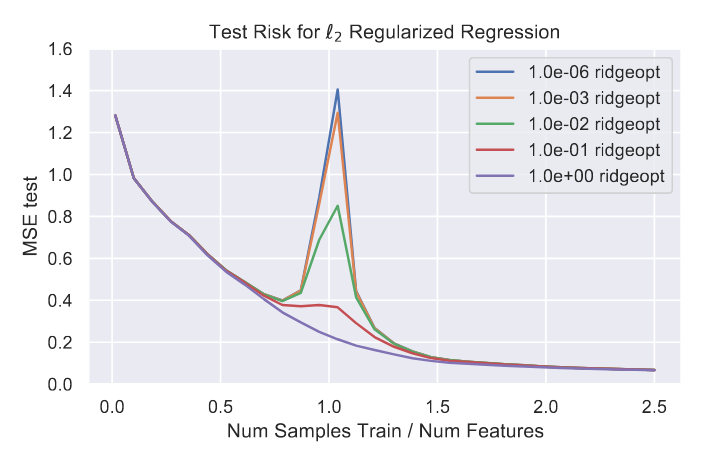 April 29, 2021: Paper club Ridge Regularization: an Essential Concept in Data Science by Trevor Hastie with Florent Bascou at ML-MTP seminar - Univ. Montpellier IMAG
April 29, 2021: Paper club Ridge Regularization: an Essential Concept in Data Science by Trevor Hastie with Florent Bascou at ML-MTP seminar - Univ. Montpellier IMAG